The lares package has multiple families of functions to
help the analyst or data scientist achieve quality robust analysis
without the need of much coding. One of the most complex but valuable
functions we have is h2o_automl, which semi-automatically
runs the whole pipeline of a Machine Learning model given a dataset and
some customizable parameters. AutoML enables you to
train high-quality models specific to your needs and accelerate the
research and development process.
HELP: Before getting to the code, I recommend
checking h2o_automl’s full documentation here
or within your R session by running ?lares::h2o_automl. In
it you’ll find a brief description of all the parameters you can set
into the function to get exactly what you need and control how it
behaves.
Pipeline
In short, these are some of the things that happen on its backend:

Mapping h2o_automl
Input a dataframe
dfand choose which one is the dependent variable (y) you’d like to predict. You may set/change theseedargument to guarantee reproducibility of your results.The function decides if it’s a classification (categorical) or regression (continuous) model looking at the dependent variable’s (
y) class and number of unique values, which can be control with thethreshparameter.The dataframe will be split in two: test and train datasets. The proportion of this split can be control with the
splitargument. This can be replicated with themsplit()function.You could also
centerandscaleyour numerical values before you continue, use theno_outliersto exclude some outliers, and/orimputemissing values withMICE. If it’s a classification model, the function can balance (under-sample) your training data. You can control this behavior with thebalanceargument. Until here, you can replicate the whole process with themodel_preprocess()function.Runs
h2o::h2o.automl(...)to train multiple models and generate a leaderboard with the top (max_modelsormax_time) models trained, sorted by their performance. You can also customize some additional arguments such asnfoldsfor k-fold cross-validations,exclude_algosandinclude_algosto exclude or include some algorithms, and any other additional argument you wish to pass to the mother function.The best model given the default performance metric (which can be changed with
stopping_metricparameter) evaluated with cross-validation (customize it withnfolds), will be selected to continue. You can also use the functionh2o_selectmodel()to select another model and recalculate/plot everything again using this alternate model.Performance metrics and plots will be calculated and rendered given the test predictions and test actual values (which were NOT passed to the models as inputs to be trained with). That way, your model’s performance metrics shouldn’t be biased. You can replicate these calculations with the
model_metrics()function.A list with all the inputs, leaderboard results, best selected model, performance metrics, and plots. You can either (play) see the results on console or export them using the
export_results()function.
Load the library
Now, let’s (install and) load the library, the data, and dig in:
# install.packages("lares")
library(lares)
# The data we'll use is the Titanic dataset
data(dft)
df <- subset(dft, select = -c(Ticket, PassengerId, Cabin))NOTE: I’ll randomly set some parameters on each example to give visibility on some of the arguments you can set to your models. Be sure to also check all the print, warnings, and messages shown throughout the process as they may have relevant information regarding your inputs and the backend operations.
Modeling examples
Let’s have a look at three specific examples: classification models (binary and multiple categories) and a regression model. Also, let’s see how we can export our models and put them to work on any environment.
Classification: Binary
Let’s begin with a binary (TRUE/FALSE) model to predict if each
passenger Survived:
r <- h2o_automl(df, y = Survived, max_models = 1, impute = FALSE, target = "TRUE")
#> 2024-01-17 10:33:55.063231 | Started process...
#> - DEPENDENT VARIABLE: Survived
#> - MODEL TYPE: Classification
#>
[38;5;246m# A tibble: 2 × 5
[39m
#> tag n p order pcum
#>
[3m
[38;5;246m<lgl>
[39m
[23m
[3m
[38;5;246m<int>
[39m
[23m
[3m
[38;5;246m<dbl>
[39m
[23m
[3m
[38;5;246m<int>
[39m
[23m
[3m
[38;5;246m<dbl>
[39m
[23m
#>
[38;5;250m1
[39m FALSE 549 61.6 1 61.6
#>
[38;5;250m2
[39m TRUE 342 38.4 2 100
#> - MISSINGS: The following variables contain missing observations: Age (19.87%). Consider using the impute parameter.
#> - CATEGORICALS: There are 3 non-numerical features. Consider using ohse() or equivalent prior to encode categorical variables.
#> >>> Splitting data: train = 0.7 && test = 0.3
#> train_size test_size
#> 623 268
#> - REPEATED: There were 68 repeated rows which are being suppressed from the train dataset
#> - ALGORITHMS: excluded 'StackedEnsemble', 'DeepLearning'
#> - CACHE: Previous models are not being erased. You may use 'start_clean' [clear] or 'project_name' [join]
#> - UI: You may check results using H2O Flow's interactive platform: http://localhost:54321/flow/index.html
#> >>> Iterating until 1 models or 600 seconds...
#>
|
| | 0%
|
|======================================================================| 100%
#> - EUREKA: Succesfully generated 1 models
#> model_id auc logloss aucpr
#> 1 XGBoost_1_AutoML_1_20240117_103355 0.8567921 0.4447956 0.8405753
#> mean_per_class_error rmse mse
#> 1 0.2091642 0.3748327 0.1404995
#> SELECTED MODEL: XGBoost_1_AutoML_1_20240117_103355
#> - NOTE: The following variables were the least important: SibSp, Parch, Embarked.S
#> >>> Running predictions for Survived...
#>
|
| | 0%
|
|======================================================================| 100%
#>
|
| | 0%
|
|======================================================================| 100%
#> Target value: TRUE
#> Warning in .font_global(font, quiet = FALSE): Font 'Arial Narrow' is not
#> installed, has other name, or can't be found
#> >>> Generating plots...
#> Model (1/1): XGBoost_1_AutoML_1_20240117_103355
#> Dependent Variable: Survived
#> Type: Classification (2 classes)
#> Algorithm: XGBOOST
#> Split: 70% training data (of 891 observations)
#> Seed: 0
#>
#> Test metrics:
#> AUC = 0.8091
#> ACC = 0.20149
#> PRC = 0.17127
#> TPR = 0.32632
#> TNR = 0.13295
#>
#> Most important variables:
#> Sex.female (39.4%)
#> Fare (18.0%)
#> Age (12.7%)
#> Sex.male (11.0%)
#> Pclass.3 (10.0%)
#> Warning in value[[3L]](cond): beep() could not play the sound due to the following error:
#> Error in play.default(x, rate, ...): no audio drivers are available
#> Process duration: 8.17sLet’s take a look at the plots generated into a single dashboard:
plot(r)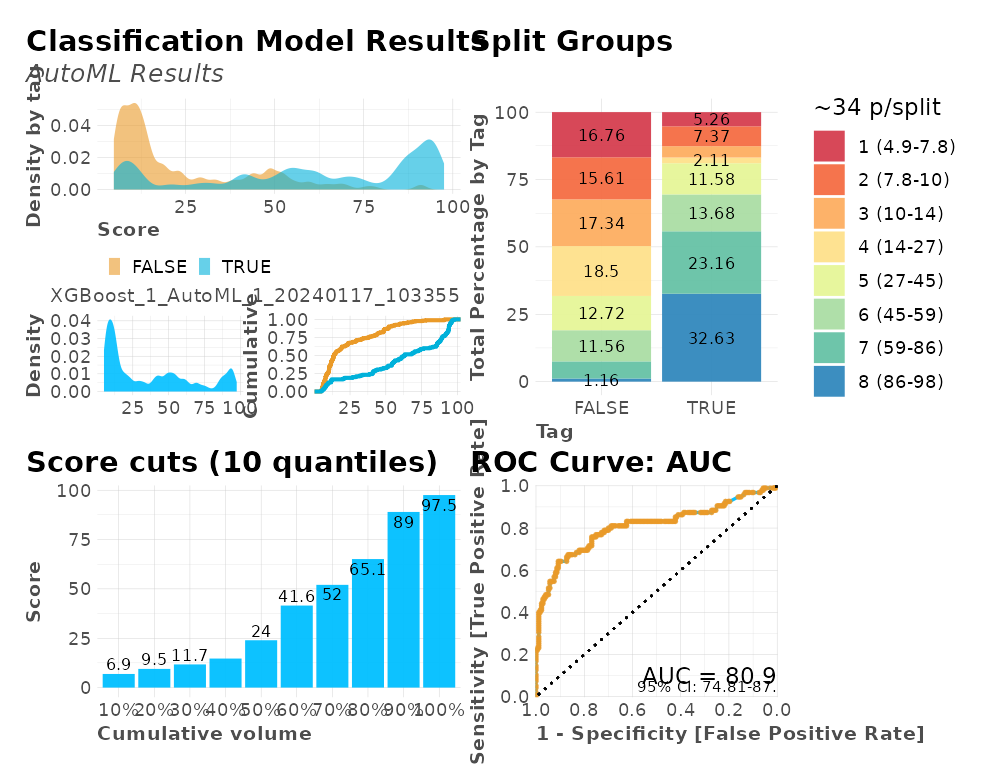
We also have several calculations for our model’s performance that may come useful such as a confusion matrix, gain and lift by percentile, area under the curve (AUC), accuracy (ACC), recall or true positive rate (TPR), cross-validation metrics, exact thresholds to maximize each metric, and others:
r$metrics
#> $dictionary
#> [1] "AUC: Area Under the Curve"
#> [2] "ACC: Accuracy"
#> [3] "PRC: Precision = Positive Predictive Value"
#> [4] "TPR: Sensitivity = Recall = Hit rate = True Positive Rate"
#> [5] "TNR: Specificity = Selectivity = True Negative Rate"
#> [6] "Logloss (Error): Logarithmic loss [Neutral classification: 0.69315]"
#> [7] "Gain: When best n deciles selected, what % of the real target observations are picked?"
#> [8] "Lift: When best n deciles selected, how much better than random is?"
#>
#> $confusion_matrix
#> Pred
#> Real FALSE TRUE
#> FALSE 23 150
#> TRUE 64 31
#>
#> $gain_lift
#> # A tibble: 10 × 10
#> percentile value random target total gain optimal lift response score
#> <fct> <chr> <dbl> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 TRUE 10.4 26 28 27.4 29.5 162. 27.4 88.9
#> 2 2 TRUE 20.5 20 27 48.4 57.9 136. 21.1 64.5
#> 3 3 TRUE 30.2 15 26 64.2 85.3 112. 15.8 52.0
#> 4 4 TRUE 39.9 7 26 71.6 100 79.3 7.37 42.3
#> 5 5 TRUE 50 9 27 81.1 100 62.1 9.47 24.4
#> 6 6 TRUE 60.1 2 27 83.2 100 38.4 2.11 14.8
#> 7 7 TRUE 70.5 4 28 87.4 100 23.9 4.21 11.7
#> 8 8 TRUE 79.9 2 25 89.5 100 12.1 2.11 9.46
#> 9 9 TRUE 89.9 7 27 96.8 100 7.69 7.37 6.90
#> 10 10 TRUE 100 3 27 100 100 0 3.16 4.86
#>
#> $metrics
#> AUC ACC PRC TPR TNR
#> 1 0.8091 0.20149 0.17127 0.32632 0.13295
#>
#> $cv_metrics
#> # A tibble: 20 × 8
#> metric mean sd cv_1_valid cv_2_valid cv_3_valid cv_4_valid cv_5_valid
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 accuracy 0.819 0.0550 0.784 0.88 0.84 0.742 0.847
#> 2 auc 0.854 0.0540 0.835 0.903 0.879 0.769 0.886
#> 3 err 0.181 0.0550 0.216 0.12 0.16 0.258 0.153
#> 4 err_cou… 22.6 6.80 27 15 20 32 19
#> 5 f0point5 0.778 0.0912 0.693 0.867 0.813 0.669 0.850
#> 6 f1 0.769 0.0630 0.738 0.862 0.767 0.692 0.787
#> 7 f2 0.764 0.0591 0.788 0.858 0.727 0.717 0.732
#> 8 lift_to… 2.53 0.174 2.72 2.27 2.66 2.53 2.48
#> 9 logloss 0.445 0.0703 0.460 0.385 0.396 0.559 0.424
#> 10 max_per… 0.250 0.0633 0.241 0.145 0.298 0.265 0.3
#> 11 mcc 0.627 0.109 0.567 0.756 0.654 0.474 0.682
#> 12 mean_pe… 0.809 0.0495 0.793 0.877 0.813 0.741 0.823
#> 13 mean_pe… 0.191 0.0495 0.207 0.123 0.187 0.259 0.177
#> 14 mse 0.141 0.0269 0.145 0.116 0.123 0.184 0.134
#> 15 pr_auc 0.835 0.0663 0.816 0.910 0.845 0.734 0.869
#> 16 precisi… 0.787 0.117 0.667 0.870 0.846 0.655 0.897
#> 17 r2 0.410 0.116 0.375 0.530 0.475 0.228 0.443
#> 18 recall 0.763 0.0722 0.826 0.855 0.702 0.735 0.7
#> 19 rmse 0.374 0.0348 0.381 0.340 0.351 0.429 0.366
#> 20 specifi… 0.855 0.0946 0.759 0.9 0.923 0.747 0.946
#>
#> $max_metrics
#> metric threshold value idx
#> 1 max f1 0.39583954 0.7485149 196
#> 2 max f2 0.19662088 0.8210059 275
#> 3 max f0point5 0.68157399 0.7979334 115
#> 4 max accuracy 0.51089102 0.8025682 156
#> 5 max precision 0.97527826 1.0000000 0
#> 6 max recall 0.03124291 1.0000000 399
#> 7 max specificity 0.97527826 1.0000000 0
#> 8 max absolute_mcc 0.68157399 0.5843403 115
#> 9 max min_per_class_accuracy 0.38232264 0.7854251 204
#> 10 max mean_per_class_accuracy 0.39583954 0.7908358 196
#> 11 max tns 0.97527826 376.0000000 0
#> 12 max fns 0.97527826 246.0000000 0
#> 13 max fps 0.03124291 376.0000000 399
#> 14 max tps 0.03124291 247.0000000 399
#> 15 max tnr 0.97527826 1.0000000 0
#> 16 max fnr 0.97527826 0.9959514 0
#> 17 max fpr 0.03124291 1.0000000 399
#> 18 max tpr 0.03124291 1.0000000 399The same goes for the plots generated for these metrics. We have the gains and response plots on test data-set, confusion matrix, and ROC curves.
r$plots$metrics
#> $gains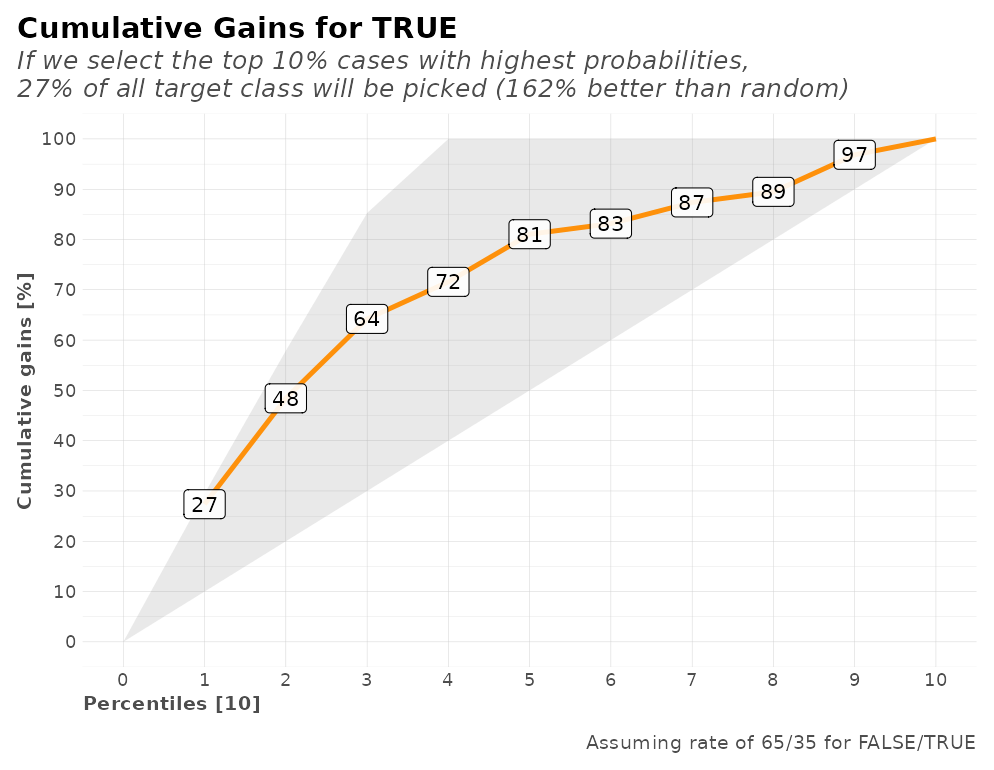
#>
#> $response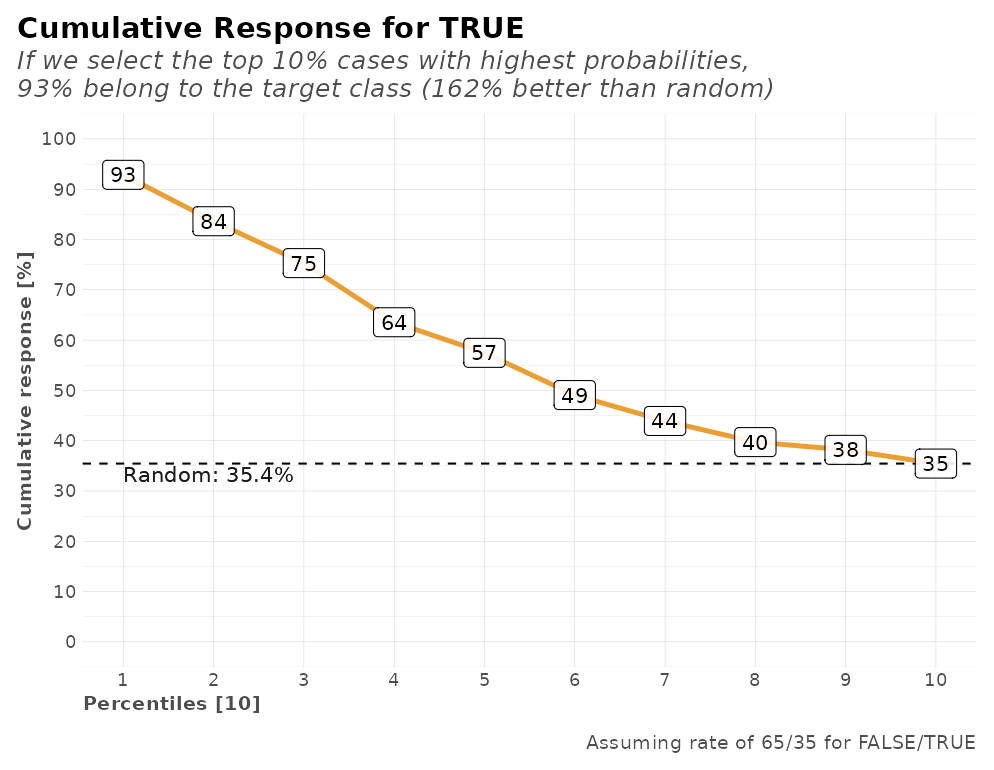
#>
#> $conf_matrix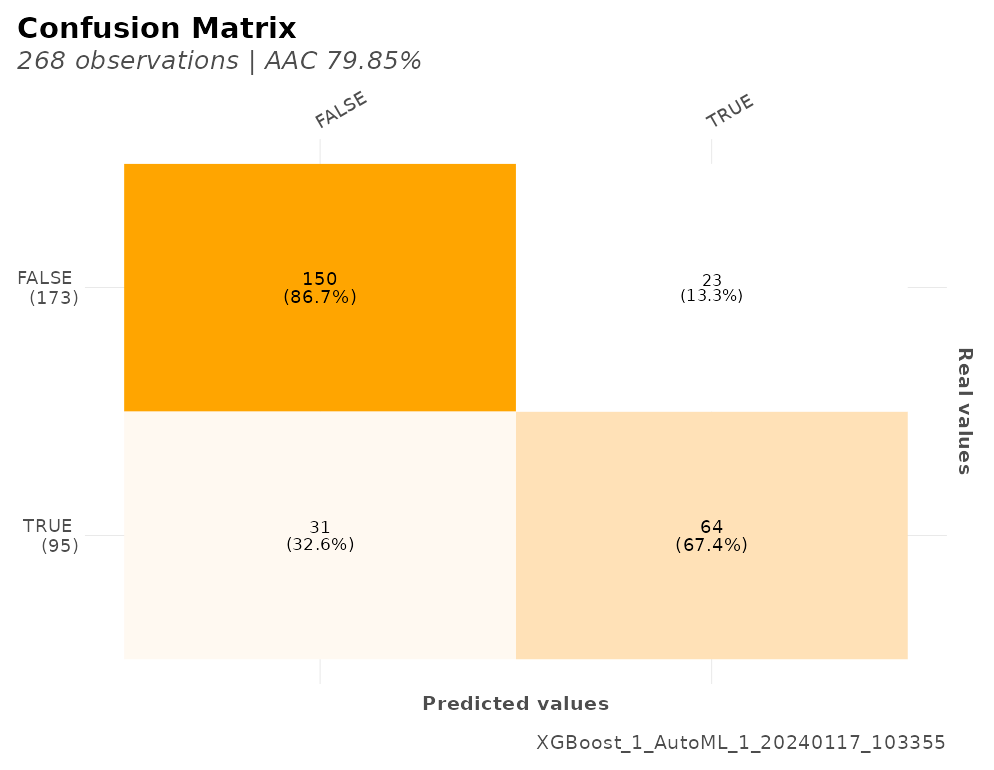
#>
#> $ROC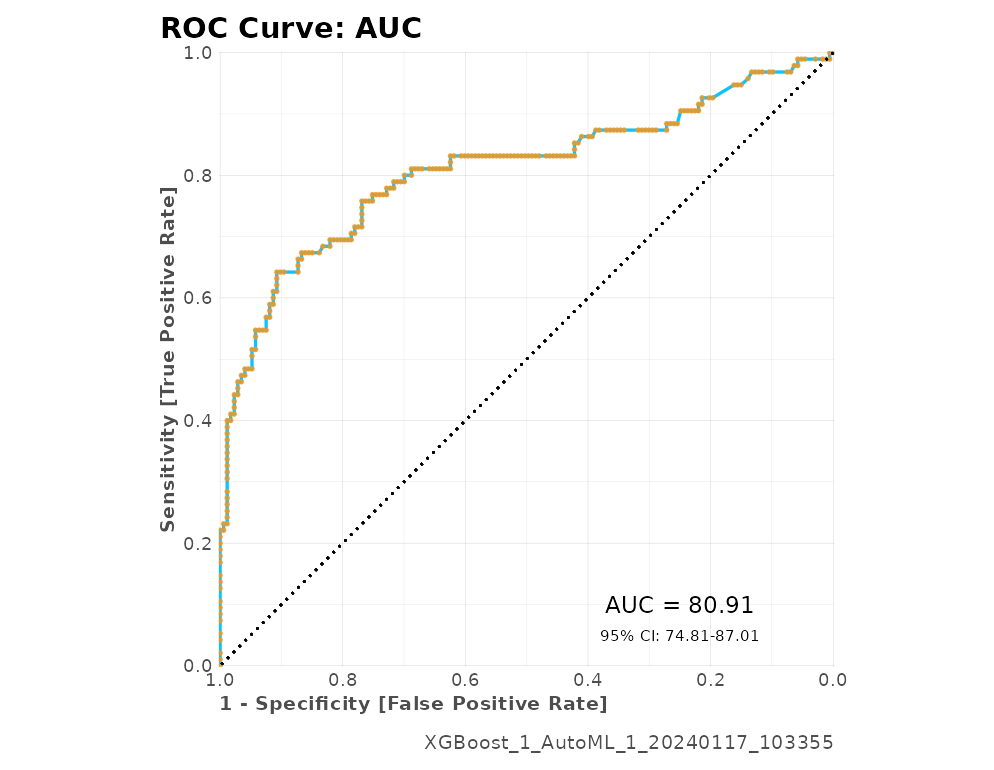
For all models, regardless of their type (classification or regression), you can check the importance of each variable as well:
head(r$importance)
#> variable relative_importance scaled_importance importance
#> 1 Sex.female 205.67552 1.0000000 0.39416611
#> 2 Fare 93.75828 0.4558553 0.17968271
#> 3 Age 66.39441 0.3228114 0.12724133
#> 4 Sex.male 57.28247 0.2785089 0.10977878
#> 5 Pclass.3 52.22692 0.2539287 0.10009009
#> 6 Pclass.1 26.51088 0.1288966 0.05080668
r$plots$importance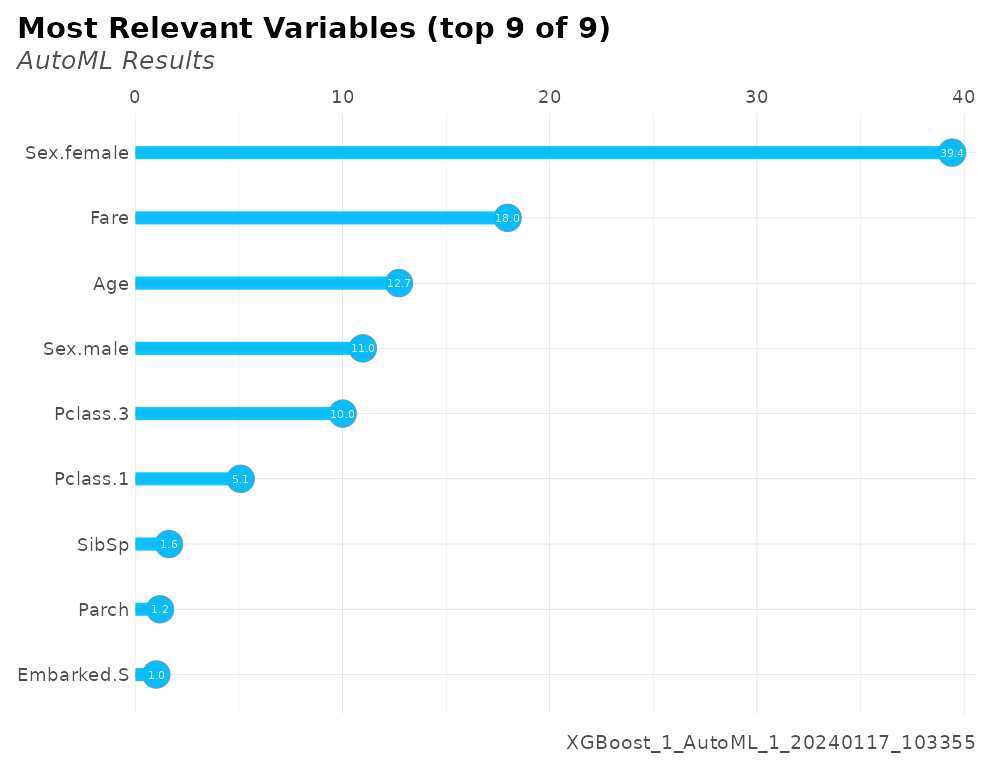
Classification: Multi-Categorical
Now, let’s run a multi-categorical (+2 labels) model to predict
Pclass of each passenger:
r <- h2o_automl(df, Pclass, ignore = c("Fare", "Cabin"), max_time = 30, plots = FALSE)
#> 2024-01-17 10:34:06.401047 | Started process...
#> - DEPENDENT VARIABLE: Pclass
#> - MODEL TYPE: Classification
#>
[38;5;246m# A tibble: 3 × 5
[39m
#> tag n p order pcum
#>
[3m
[38;5;246m<fct>
[39m
[23m
[3m
[38;5;246m<int>
[39m
[23m
[3m
[38;5;246m<dbl>
[39m
[23m
[3m
[38;5;246m<int>
[39m
[23m
[3m
[38;5;246m<dbl>
[39m
[23m
#>
[38;5;250m1
[39m n_3 491 55.1 1 55.1
#>
[38;5;250m2
[39m n_1 216 24.2 2 79.4
#>
[38;5;250m3
[39m n_2 184 20.6 3 100
#> - MISSINGS: The following variables contain missing observations: Age (19.87%). Consider using the impute parameter.
#> - CATEGORICALS: There are 3 non-numerical features. Consider using ohse() or equivalent prior to encode categorical variables.
#> >>> Splitting data: train = 0.7 && test = 0.3
#> train_size test_size
#> 623 268
#> - REPEATED: There were 65 repeated rows which are being suppressed from the train dataset
#> - ALGORITHMS: excluded 'StackedEnsemble', 'DeepLearning'
#> - CACHE: Previous models are not being erased. You may use 'start_clean' [clear] or 'project_name' [join]
#> - UI: You may check results using H2O Flow's interactive platform: http://localhost:54321/flow/index.html
#> >>> Iterating until 3 models or 30 seconds...
#> - EUREKA: Succesfully generated 3 models
#> model_id mean_per_class_error logloss rmse
#> 1 GLM_1_AutoML_2_20240117_103406 0.4742325 0.8170807 0.5409388
#> 2 XGBoost_1_AutoML_2_20240117_103406 0.4990997 0.8229646 0.5387748
#> 3 GBM_1_AutoML_2_20240117_103406 0.5046914 0.8579317 0.5592290
#> mse
#> 1 0.2926147
#> 2 0.2902783
#> 3 0.3127371
#> SELECTED MODEL: GLM_1_AutoML_2_20240117_103406
#> - NOTE: The following variables were the least important: Sex.male, Sex.female, Parch
#> >>> Running predictions for Pclass...
#>
|
| | 0%
|
|======================================================================| 100%
#>
|
| | 0%
|
|======================================================================| 100%
#> Model (1/3): GLM_1_AutoML_2_20240117_103406
#> Dependent Variable: Pclass
#> Type: Classification (3 classes)
#> Algorithm: GLM
#> Split: 70% training data (of 891 observations)
#> Seed: 0
#>
#> Test metrics:
#> AUC = 0.76337
#> ACC = 0.64179
#>
#> Most important variables:
#> Embarked.Q (25.3%)
#> Embarked.C (13.5%)
#> Embarked.S (13.3%)
#> Age (11.9%)
#> Survived.FALSE (10.6%)
#> Warning in value[[3L]](cond): beep() could not play the sound due to the following error:
#> Error in play.default(x, rate, ...): no audio drivers are available
#> Process duration: 11.5sLet’s take a look at the plots generated into a single dashboard:
plot(r)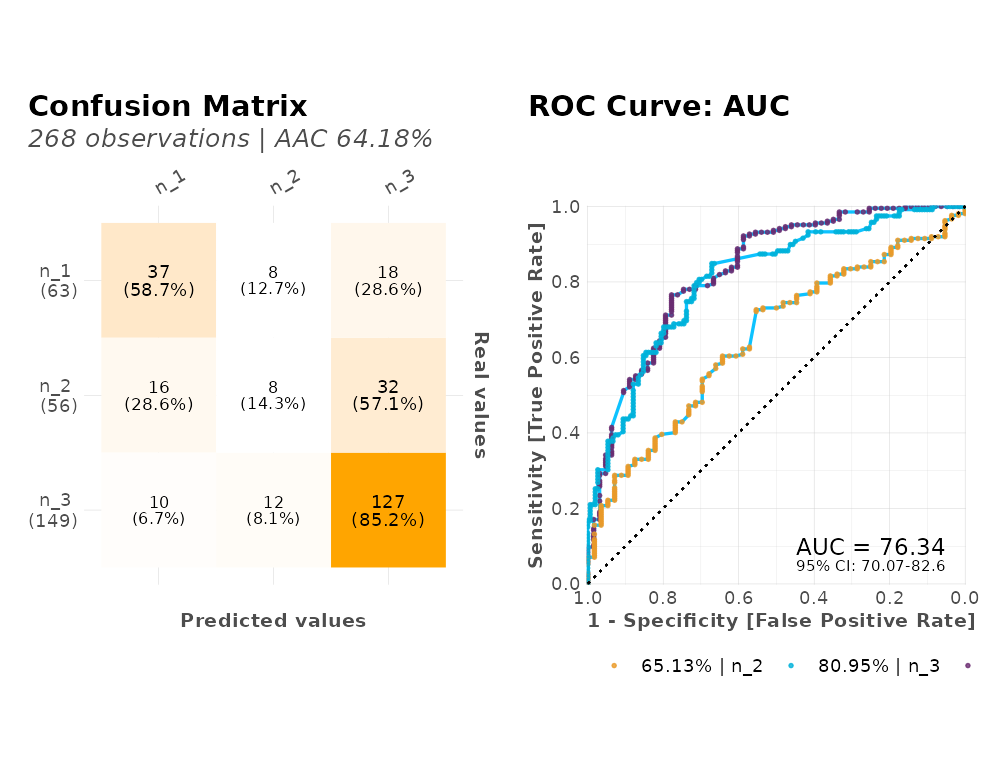
Regression
Finally, a regression model with continuous values to predict
Fare payed by passenger:
r <- h2o_automl(df, y = "Fare", ignore = "Pclass", exclude_algos = NULL, quiet = TRUE)
print(r)
#> Model (1/4): StackedEnsemble_BestOfFamily_1_AutoML_3_20240117_103419
#> Dependent Variable: Fare
#> Type: Regression
#> Algorithm: STACKEDENSEMBLE
#> Split: 70% training data (of 871 observations)
#> Seed: 0
#>
#> Test metrics:
#> rmse = 20.061
#> mae = 14.129
#> mape = 0.070818
#> mse = 402.45
#> rsq = 0.3661
#> rsqa = 0.3637Let’s take a look at the plots generated into a single dashboard:
plot(r)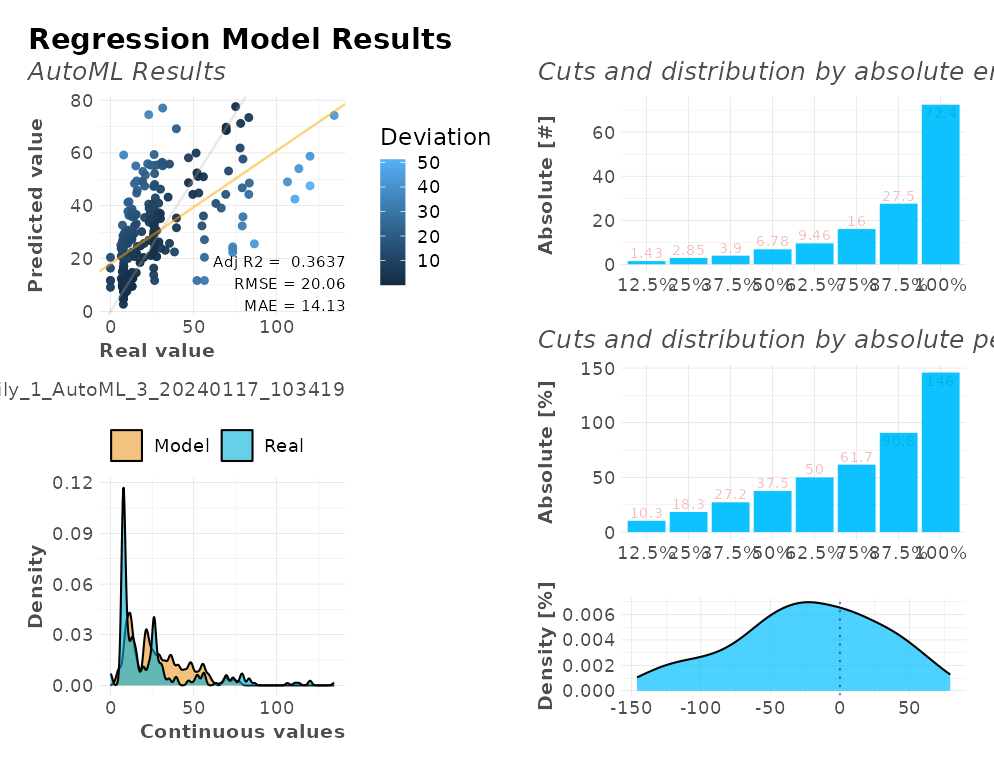
Export models and results
Once you have you model trained and picked, you can export the model
and it’s results, so you can put it to work in a production environment
(doesn’t have to be R). There is a function that does all that for you:
export_results(). Simply pass your h2o_automl
list object into this function and that’s it! You can select which
formats will be exported using the which argument.
Currently we support: txt, csv,
rds, binary, mojo [best format
for production], and plots. There are also 2 quick options
(dev and production) to export some or all the
files. Lastly, you can set a custom subdir to gather
everything into a new sub-directory; I’d recommend using the model’s
name or any other convention that helps you know which one’s which.
Import and use your models
If you’d like to re-use your exported models to predict new datasets, you have several options:
-
h2o_predict_MOJO()[recommended]: This function lets the user predict usingh2o’s.zipfile containing the MOJO files. These files are also the ones used when putting the model into production on any other environment. Also, MOJO let’s you changeh2o’s versions without issues -
h2o_predict_binary(): This function lets the user predict using the h2o binary file. Theh2oversion/build must match for it to work. -
h2o_predict_model(): This function lets the user run predictions from aH2O Model Objectsame as you’d use thepredictbase function. Will probably only work in your current session as you must have the actual trained object to use it.
Addittional Posts
- DataScience+: Visualizations for Classification Models Results
- DataScience+: Visualizations for Regression Models Results